Four specific breakthroughs
PANN™ advances existing IT and electronic technology overall via four specific technical breakthroughs:
- Software: PANN™ permits development of “smart” software with high processing speed and unlimited volume of processed information. The worldwide software market is about $400B. Existing ANN’s captured less than $20B due to their limitations. PANN™ has no such limitations.
- GPU: PANN™ is extremely fast on Graphical Process Units. This make possible creation of a Supercomputer based on a GPU and PANN™ combination. Market of GPU supercomputers is already about $18B.
- Microchip: Creation of the next-generation neural microchip based on PANN™. With this microchip a Supercomputer and a Hypercomputer can be built. Today’s microchip market is about $400B. Licensing the technology to at least 20% of chip producers for 1% license fee will generate $800M annually.
- Optical Chip: Creation of the optical microchip and optical storage based on PANN™. Optical computation is the next big thing after digital electronics. The market of optical calculations will gradually grow with replacement of existing computer systems by optical systems, starting in 2020.

Unique features of PANN™
- High-speed training (with high accuracy) for approximation, classification and interpolation.
- Training on CPU is at least 3,000 times faster in comparison with existing ANN
- Training with one GPU is 200,000 times faster and proportional to the number of GPUs
- 100%-parallel computation; linear increase in training speed with additional GPUs.
- Batch training of the entire training set: weight correction after every epoch of images, not after every image. Recognition of the entire batch of images, not of a single image, one after another.
- Ability to train the network with additional images without retraining the entire network.
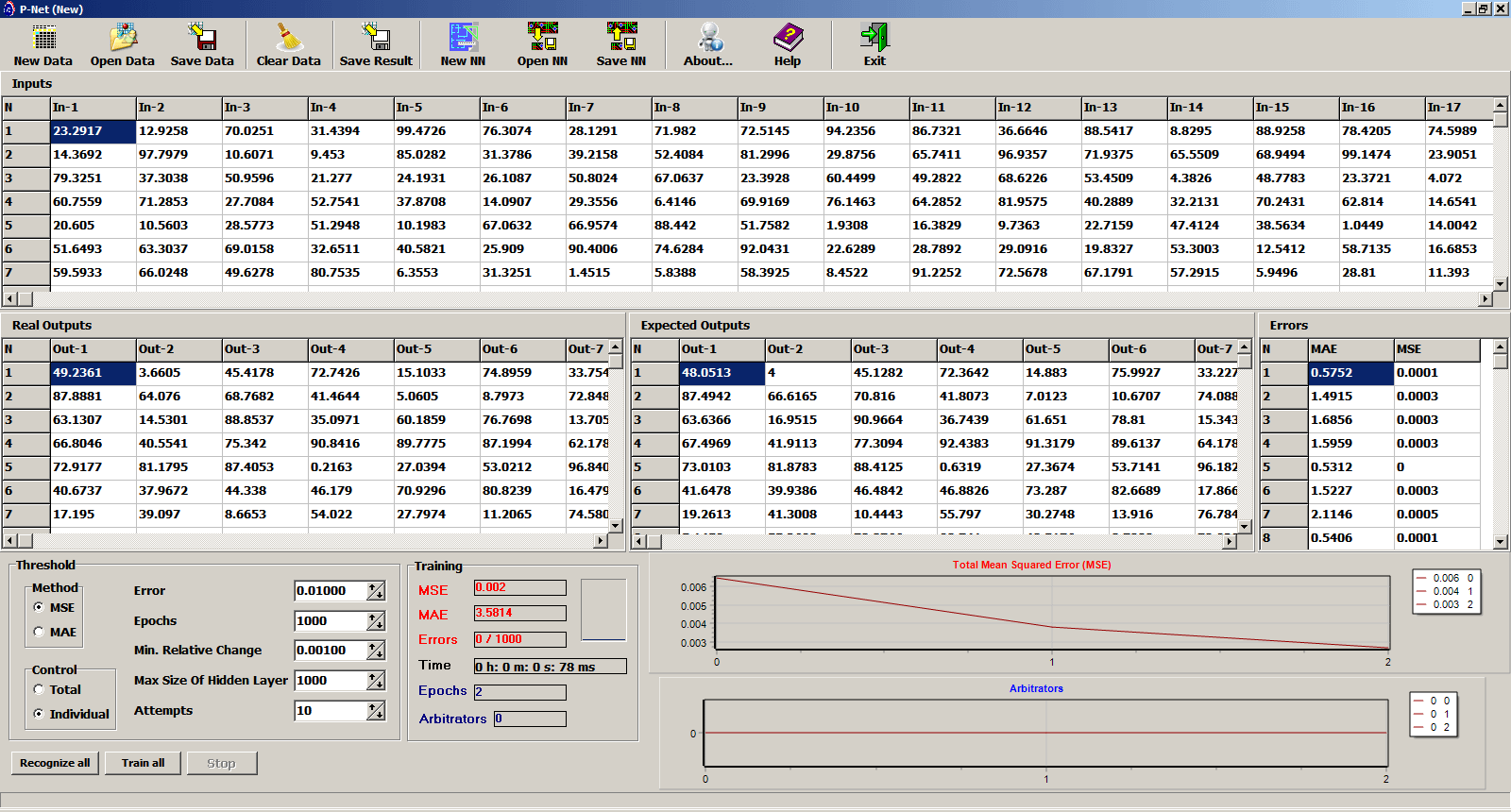
Software breakthrough
PANN™ allows to create really smart software with high processing speed and unlimited amount of processed information.
In addition:
- PANN™ is scalable. Can be built in any size.
- PANN™ architecture and training algorithm have been discovered within biological analogs.
- Complex calculations are not necessary.
- Multiple repeating calculations are not necessary.
- Calculations and weight correction by matrix algebra. (US Patent application 15/449,614)
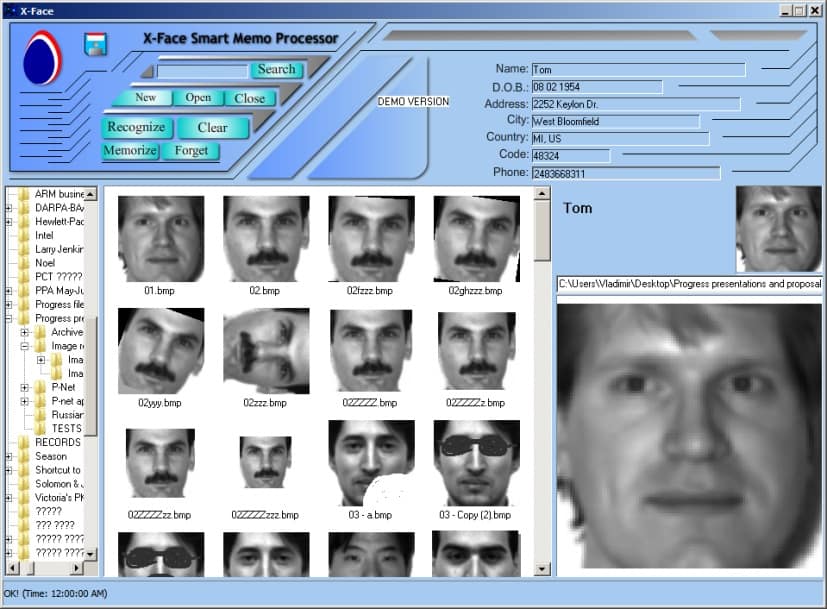
PANN™ applications
- Replacing existing ANN in order to obtain:
- High speed training
- High accuracy of training
- High reliability and scalability
- Dynamical changes of ANN stricture
- Solution for XOR and overfitting problems
- Development of the new advanced software for:
- Big and super big data
- Fast performance
- Processing unindexed data
- Data protection
- High system reliability
- Solving unsolved problems, etc.
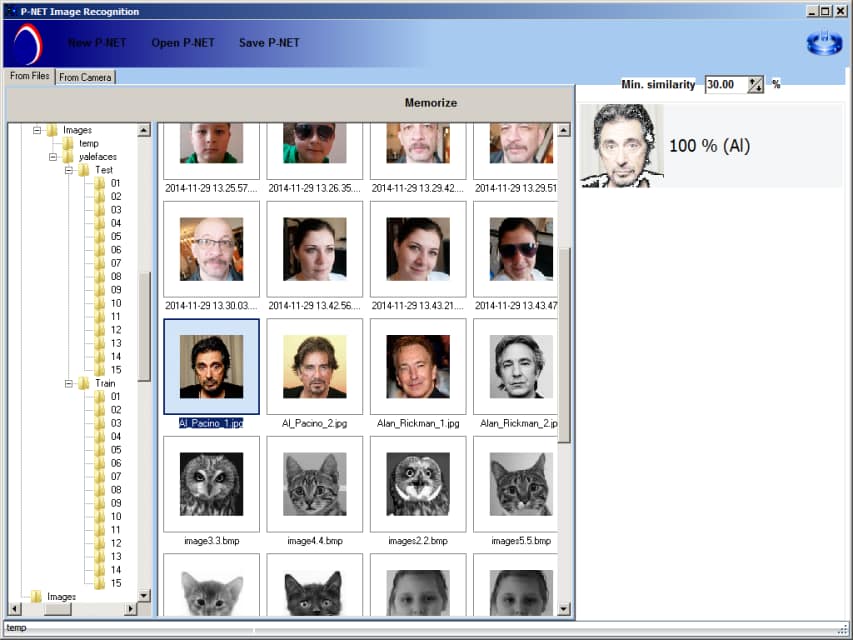
GPU breakthrough
PANN™ is extremely fast on Graphical Process Units. This makes possible creation of a Supercomputer based on both GPUs and PANN™. Market of GPUs supercomputers is already about $18B.
The market is ready for this:
- Many supercomputer development companies use GPUs for parallel mathematical operations, thus increasing calculation speed. For example, Cray, IBM, Dell, and HPE.
- Some companies use GPUs for ANN speed increasing. nVidia, for example, uses GPU to increase ANN speed 20+ times in comparison with CPU.
